实时预警

文章目录
实时预警
针对互联网数据中涉及某些话题的数量进行实时预警。例如当在某段时间,例如20分钟内,某规则我 + (蟾蜍 | 蛤蟆 | 青蛙王子) 命中数据(可自行设定命中内容或标题)2000条则进行预警(为防止短时间大量预警可设置有效预警间隔)
预警流程
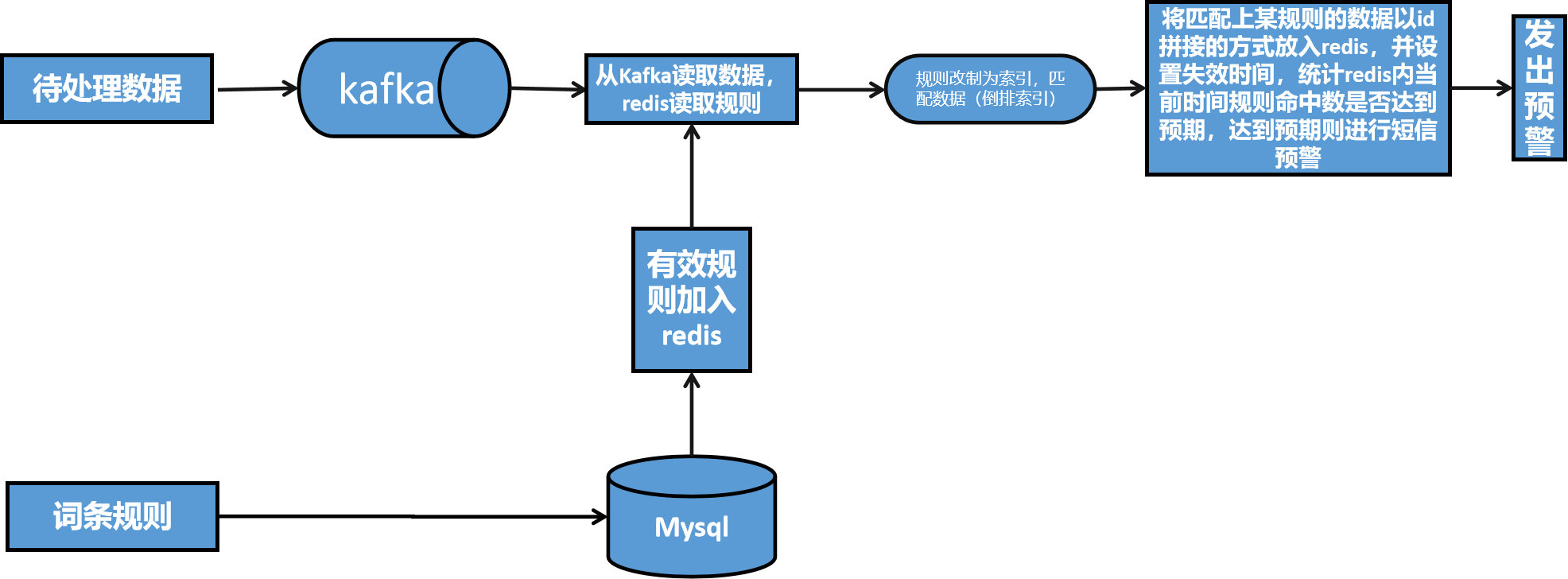
实现步骤:
1、将待处理数据放入kafka实时流Topic
2、将规则放入mysql数据然后加入redis内
3、从redis内检索规则是否新增或删改,更新索引
4、从Topic内读取数据,匹配索引,将词条规则id与数据id拼接加入redis内设置失效时间
5、统计redis内未失效的词条数据是否达到阈值
6、当规则达到阈值触发短信接口,并将触发规则的数据给予展示
匹配方式:倒排索引
倒排索引是一种索引方法,被用来存储在全文搜索下某个单词在一个文档或者一组文档中的存储位置的映射,常被应用于搜索引擎和关键字查询的问题中。
索引生成
针对规则 我 + (蟾蜍 | 蛤蟆 | 青蛙王子) ,有关键字集合 $[‘我’,‘蛤蟆’,‘蟾蜍’,‘青蛙王子’]$ ,解析关键字集合成适合检索的结构
例如对 $[‘我’,‘蛤蟆’,‘蟾蜍’,‘青蛙王子’]$ ,可构建索引结构{‘我’: 1, ‘蛤蟆’: 1, ‘蛤’: 0, ‘蟾蜍’: 1, ‘蟾’: 0, ‘青蛙王子’: 1, ‘青’: 0, ‘青蛙’: 0, ‘青蛙王’: 0}
规则预编译
针对规则 我 + (蟾蜍 | 蛤蟆 | 青蛙王子) ,首先进行特殊字符删减,获得关键词集合,然后将匹配结束的关键词转换为 $True$ $Flase$
对文本 我觉得好看的蟾蜍是青蛙 进行关键词转化后为 $True + (True|True|Flase)$
对与或非逻辑转换为 $and$ $or$ ,转换后的结果为 $True\ and \ (True\ or\ True\ or\ Flase)$
对规则进行预编译实现快速处理
匹配数据
匹配时对文本进行向后式扩展匹配
以索引结构{‘我’: 1, ‘蛤蟆’: 1, ‘蛤’: 0, ‘蟾蜍’: 1, ‘蟾’: 0, ‘青蛙王子’: 1, ‘青’: 0, ‘青蛙’: 0, ‘青蛙王’: 0} 为例
对文本 青蛙王子是益虫吗 对文本第一个字 青 匹配发现存在,则进行向后式扩匹配 青蛙 、 青蛙王 、 青蛙王子 结束,返回关键词青蛙王子。
然后对文本第二个字 蛙 ,发现不存在则向后移步。
一直到最后有个字 吗 结束 。
实现代码
|
|
文章作者 玉面蟾蜍
上次更新 2022-04-17 Sun