卷积神经网络

文章目录
CNN
CNN(卷积【对两个实变函数的一种数学运算】神经网络)主要由两部分组成:
1、特征提取(卷积、激活函数、池化)【从概率分布的视角看(bayes派)这是一种无限强的先验(这个先验说明了该层应该学得的函数只包含局部连接关系并且对平移具有等变性)】
先验被认为是强或者弱取决于先验中概率密度的集中程度:
- 弱先验具有较高的熵值,例如方差很大的高斯分布。这样的先验允许数据对于参数的改变具有较大的自由性;
- 强先验具有较低的熵值,例如方差很小的高斯分布。这样的先验在决定参数时,对最终取值时起着更大的决定性作用
2、分类识别(全连接)
两层之间所有神经元都有权重连接,通常全连接层在卷积神经网络尾部。也就是跟传统的神经网络神经元的连接方式一样
CNN详解
卷积理解
卷积本质是加权叠加,意义是对信号进行滤波
连续卷积 $\displaystyle \int^{\infty}_{-\infty} f(\tau)g(x-\tau)d\tau$
离散卷积 $\displaystyle \sum^{\infty}_{\tau=-\infty} f(\tau)g(x-\tau)$
从公式上来看我们进行了三步操作:
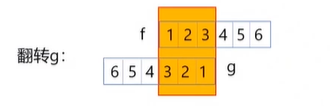
1、我们对 $g$ 函数沿着y轴翻转了180°
2、把翻转后的 $g$ 函数平移n在这个位置
3、对处理后的 $g$ 函数和 $f$ 的对应点相乘求和
翻转和平移都是为了对应相乘求积分
例如求两粒骰子加起来等于4的概率是多少就是一个典型的离散卷积
那么我们的做法是假设第一粒骰子符合离散函数 $f$ 第二粒骰子符合离散函数 $g$ 那么两粒骰子加起来等于4的概率可以表示为 $f(1)g(3)+f(2)g(2)+ f(3)g(1)$
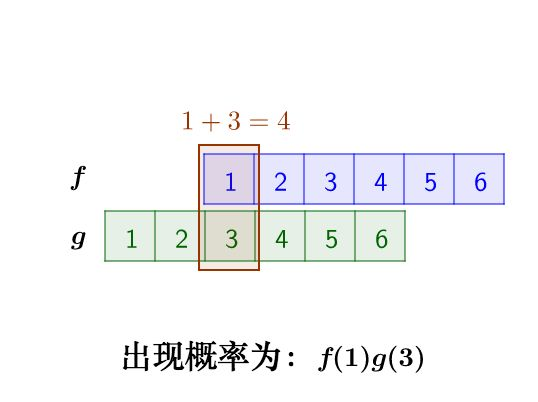
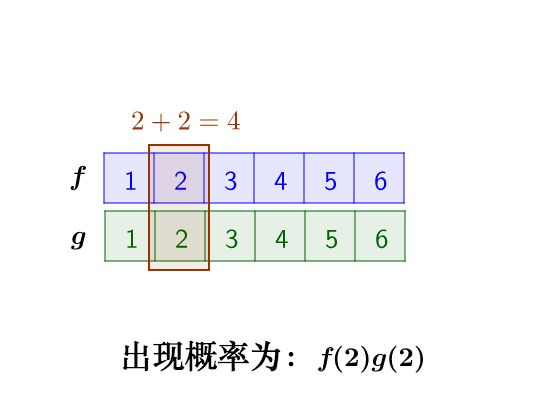
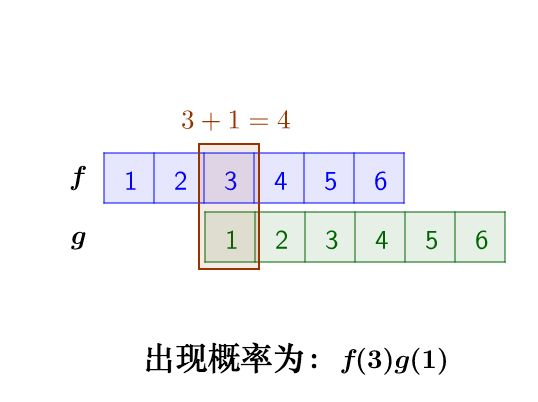
对函数 $g$ 进行翻转平移可以得到 $f(1)g(3)+f(2)g(2)+ f(3)g(1) = f(1)g(4-1)+f(2)g(4-2)+f(3)g(4-1)$
其对应的图为:
二维层面的卷积如下:
求新的某一个卷积值例如 $c_{1,1}$

在图中的展现形式为:
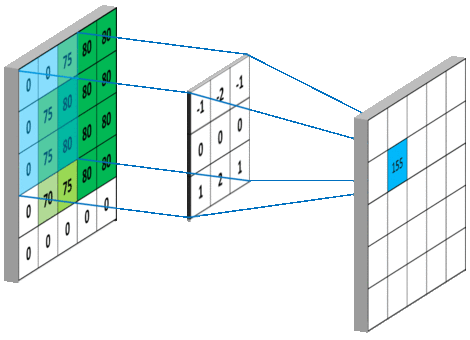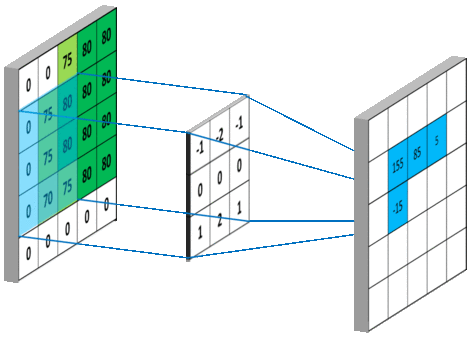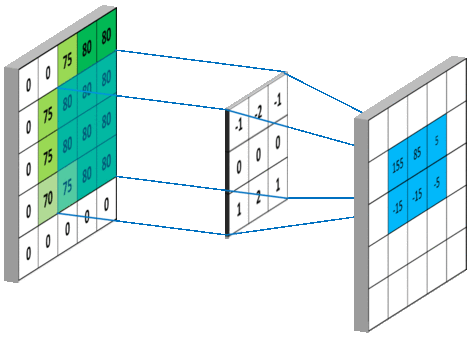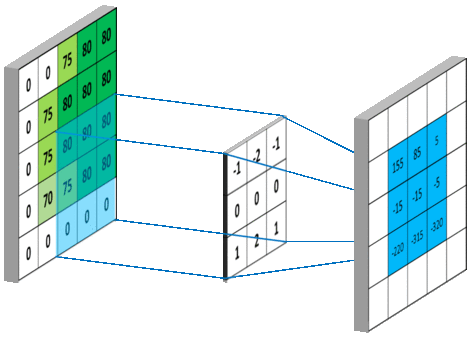
在tensorflow中padding的值可以设为SAME、VALID分别是对卷积方式的控制
SAME卷积方式指在卷积核的核心k从原矩阵第一个值开始平滑(当步长为1时,卷积后的矩阵尺寸等于原矩阵大小):
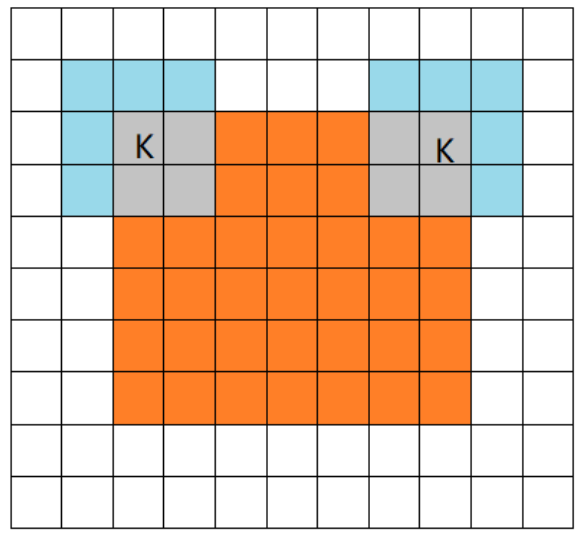
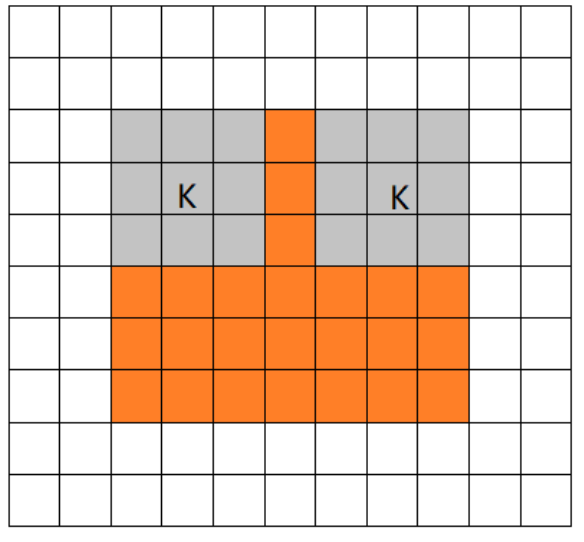
VALID卷积方式指在卷积核完全从原矩阵内开始卷积(无论步长设为多少,卷积后的矩阵尺寸小于原矩阵):
当我们使用多个卷积核时对三维数据进行处理时如下:
采用的方式为same、步长为2
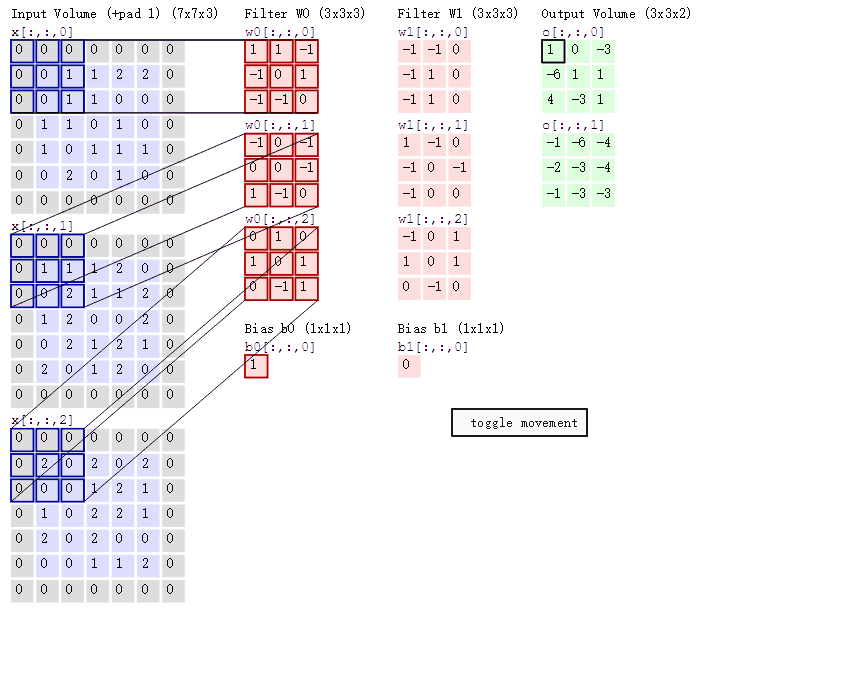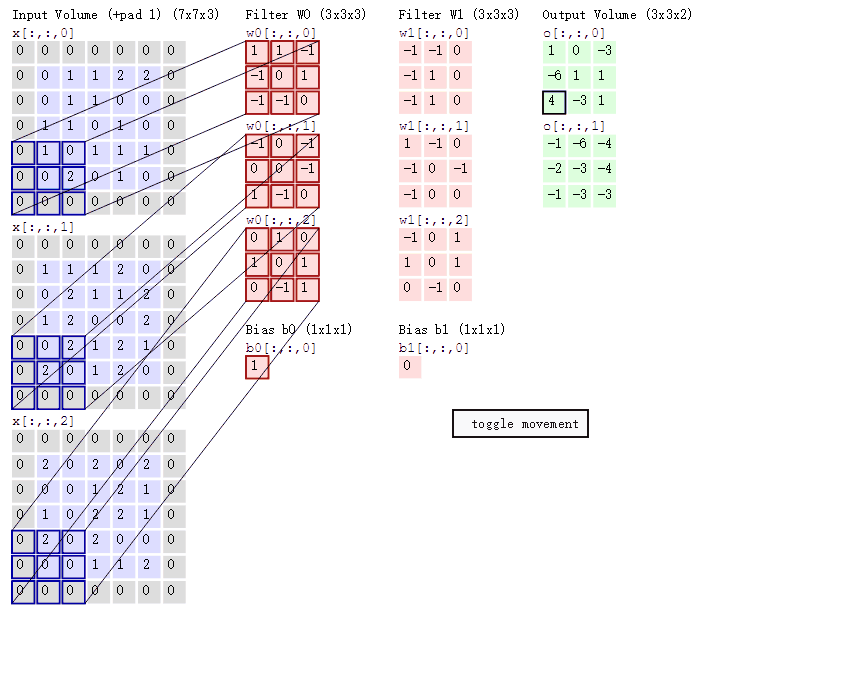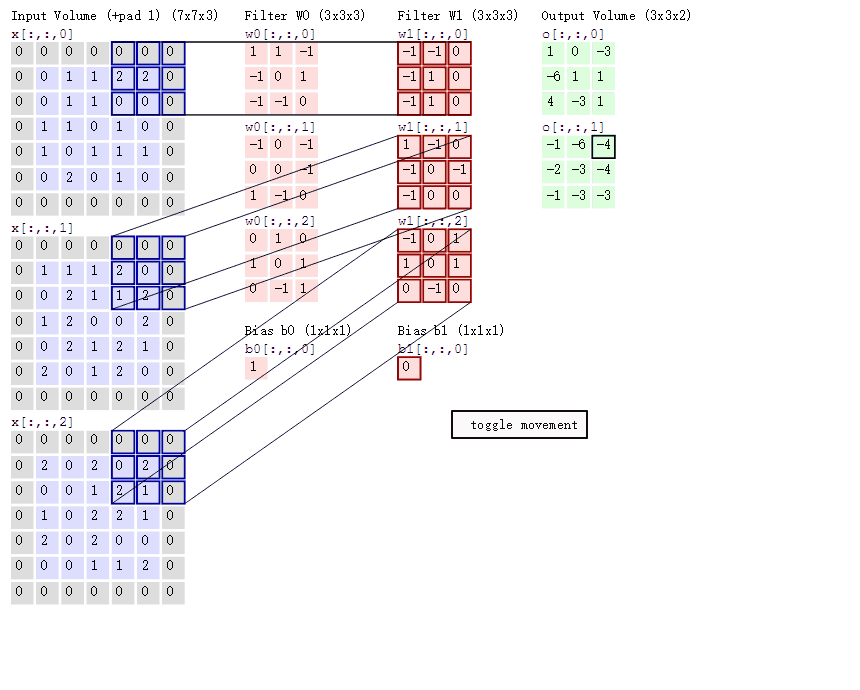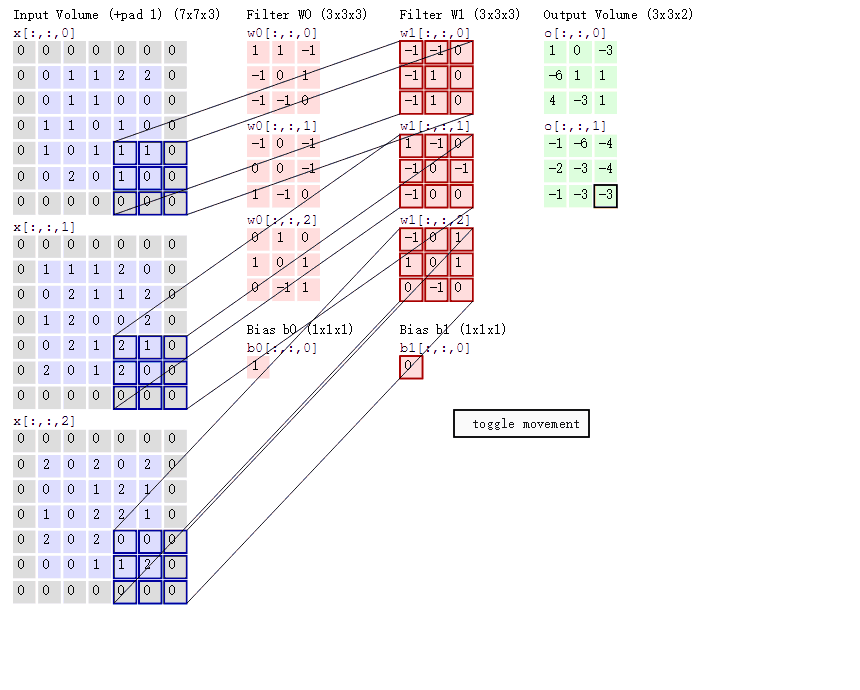
通过上述探究可知same方式输出矩阵与输入矩阵的尺寸关系: $n_{输出矩阵尺寸} = 向上取整( \displaystyle \frac{n_{输入矩阵尺寸}}{S_{步长}})$
valid方式输出矩阵与输入矩阵的尺寸关系: $n_{输出矩阵尺寸} = 向上取整( \displaystyle \frac{n_{输入矩阵尺寸}-f_{卷积核尺寸}+1}{S_{步长}})$
卷积的意义
以边缘检测卷积为例子:
|
|
边缘效果如下:

最后cnn神经网络在学习之后学到的卷积核就类似于这种,能体现图片一部分特征
卷积核的选择
常见的卷积核多为奇数
- 奇数相对于偶数,有中心点,对边沿、对线条更加敏感,可以更有效的提取边沿信息;
- 如果卷积核size是奇数,就可以从图像的两边对称的padding;
- 奇数size的卷积核,有central pixel 可以方便的确定position;
参数共享
参数共享的目的很简单就是通过降低参数量减少计算量
1、局部连接(卷积核通常采用3*3或5*5)
对一个边长为10的矩阵进行全连接卷积,如果输出矩阵的大小要求相同,那么需要参数的数量为
$10*10_{单个全连接卷积核大小}*(10*10)_{保持原输入矩阵大小}$
如果采用局部链接例如3*3矩阵,如果输出矩阵的大小要求相同,那么需要的参数数量为:
$3*3_{单个卷积核大小}*(10*10)_{保持原输入矩阵大小}$
2、在一个卷积核(滤波器)平滑的过程中,原数据共享一个卷积核参数
即只是卷积核大小+偏置数
能采用参数共享的依据是:
1、局部连接有效是因为局部视野可以反馈原始数据特征
2、单个卷积核(滤波器)就是一个特征映射,增加卷积核个数即可增加特征维度
激励函数
本质上的神经网络是矩阵运算,其核心是线性的,采用激活函数可以解决线性不能解决的问题
池化理解(下采样)
在卷积后的特征上,单个区域内的值可以被其均值或最大值替代,在生活中常见的就是像素画,如下:
池化的意义:
1、保留主要特征的同时减少参数(降低纬度,类似PCA)和计算量,防止过拟合
2、invariance(不变性),这种不变性包括translation(平移),rotation(旋转),scale(尺度,尺寸问题)
3、减少网络参数个数
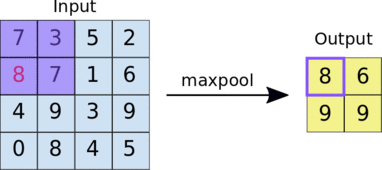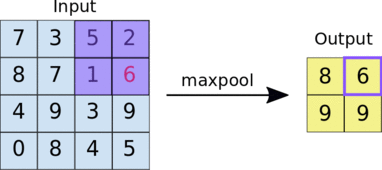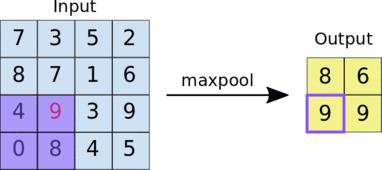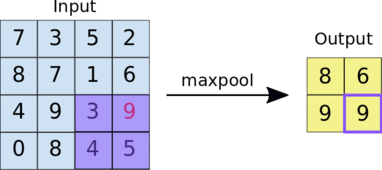
池化的实现过程,以最大池化为例:
全连接层
特征拍扁,多维度特征映射到同一个维度
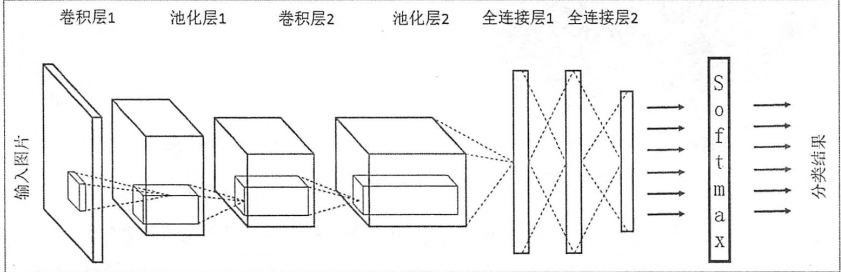
全连接层在整个网络卷积神经网络中起到“分类器”的作用。如果说卷积层、池化层和激活函数等操作是将原始数据映射到隐层特征空间的话(特征提取+选择的过程),全连接层则起到将学到的特征表示映射到样本的标记空间的作用。换句话说,就是把特征整合到一起(高度提纯特征),方便交给最后的分类器或者回归。
dropout
dropout强迫一个神经单元,和随机挑选出来的其他神经单元共同工作,达到好的效果。消除减弱了神经元节点间的联合适应性,增强了泛化能力。
对大数据量而言,当dropout=0.5时,信息熵最大,dropout随机生成的网络结构最多,所以理论上效果最好
CNN的简单使用
使用tensorflow1.15版本
|
|
反向传播推导

CNN的优缺点
优点
1、共享卷积核,可以轻松处理高维数据
2、自动进行特征提取器参数学习
缺点
1、cnn没有记忆功能
2、cnn特征检测能力很强,但是特征理解能力很差
参考:
文章作者 玉面蟾蜍
上次更新 2022-03-02 Wed